PHPで始める簡単クローラー&スクレイピング

今回は本サイトのスクラップ以前にわりと反響の多かったPHPでの簡単なクローラー、スクレイピングの方法についてご紹介します。
スクレイピングとは
スクレイピングはサーバサイドのプログラミング言語を使って外部サーバへアクセスし、そのコンテンツから自分たちの欲しい情報を引き出す手法です。
とあるように、プログラムを使用してWEB上に公開されいてるデータ(ウェブサイト等)から自分のほしいデータを取得し、データの整形・加工などを行い、独自の情報やデータを収集することをいいます。
これによって、手動での情報収集の作業を減らし、業務を効率化できたり、生産性を高めたりといった効果が期待できます。
ただし、デメリットもあるので何でもかんでもスクレイピングするのはやめましょう。
クローラーとは
スクレイピングと似た言葉にクローラーというものがあります。
クローラーとは、一般的にWEB上を巡回してウェブサイトの情報を収集するボットプログラムのことを指します。
クローリングとスクレイピングは類義語として扱われることが多いですが、巡回はせずに特定の1ページの情報だけを取得するプログラムなどはクローラーとは言えません。
ただ、このような名前に明確な定義があるわけではなく、クローラーとスクレイピングを同じような意味で使っている場合が多く、2018年現在ではクローリングをしながらスクレイピングを行うのが標準になってきています。
PHPでのスクレイピング
じつはPHPはあまりスクレイピング向きのプログラム言語ではありません。
とくに、近年流行りのReactやVue.jsなどで作成されたSPA(シングルページアプリケーション)などはJavaScriptの実行が必要不可欠になってくるのでPHPのみでは取得できないものが多いです。
ただ、PHPはわかりやすく初心者にも取り組みやすい言語なのでまずはここから始めるというのもいいと思います。
かく言う僕もはじめてのスクレイピングはPHPで行いました。
というわけで、今回はphpQueryというライブラリを使用したPHPでのスクレイピング方法を解説します。
わかりやすくscrapingという作業ディレクリで説明していきます。
phpQueryのダウンロードと設置
まずはスクレイピングをよりシンプルかつ簡単に行うためにphpQueryというライブラリを公式サイトからダウンロードしていきます。
今回はプログラムファイルのみ使えればいいのでphpQuery-0.9.5.386-onefile.zipをダウンロードしましょう。
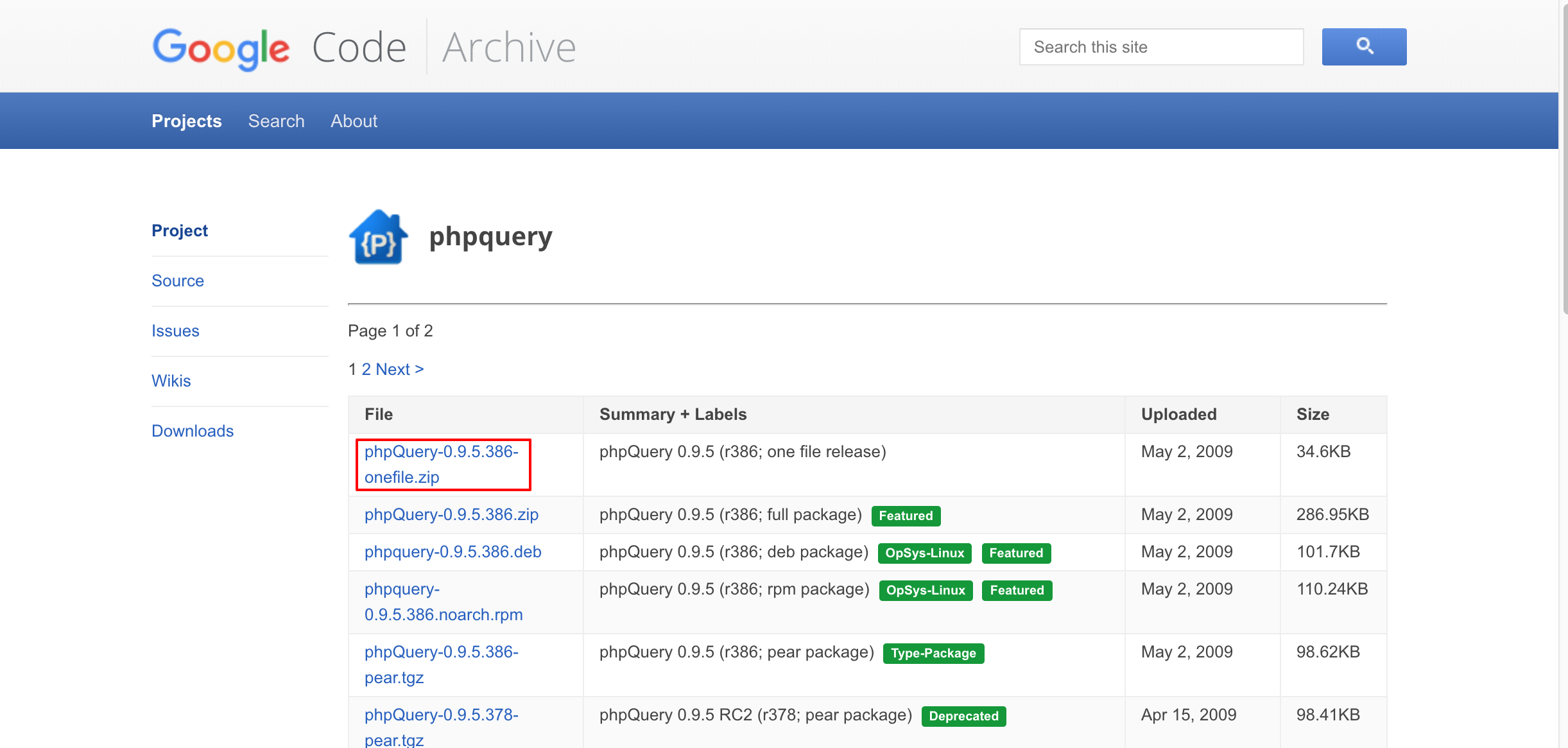
ダウンロードができたらphpQuery-onefile.phpを作業ディレクリに設置します。
phpQueryの設置が完了したらとりあえず空ファイルで構わないのでindex.phpという名前でプログラムファイルを作成します。
scraping/ ├ index.php └ phpQuery-onefile.php
これでスクレイピングの準備が整いましたので実際にスクレイピングを行っていきましょう。
スクレイピングする
サンプルでは、もはや151匹ではなくなってしまいどんな個体が何匹いるのかもわからなくなってしまったポケモンの情報をポケモンWikiからスクレイピングしながらスクレイピングしていきます。
まずはスクレイピングをしたいサイトにアクセスしてほしい情報がどこに掲載されているのかを確認しましょう。
今回はポケモンの一覧情報がほしいのでその部分がどのようなHTML構造になっているかを検証で確認していきます。
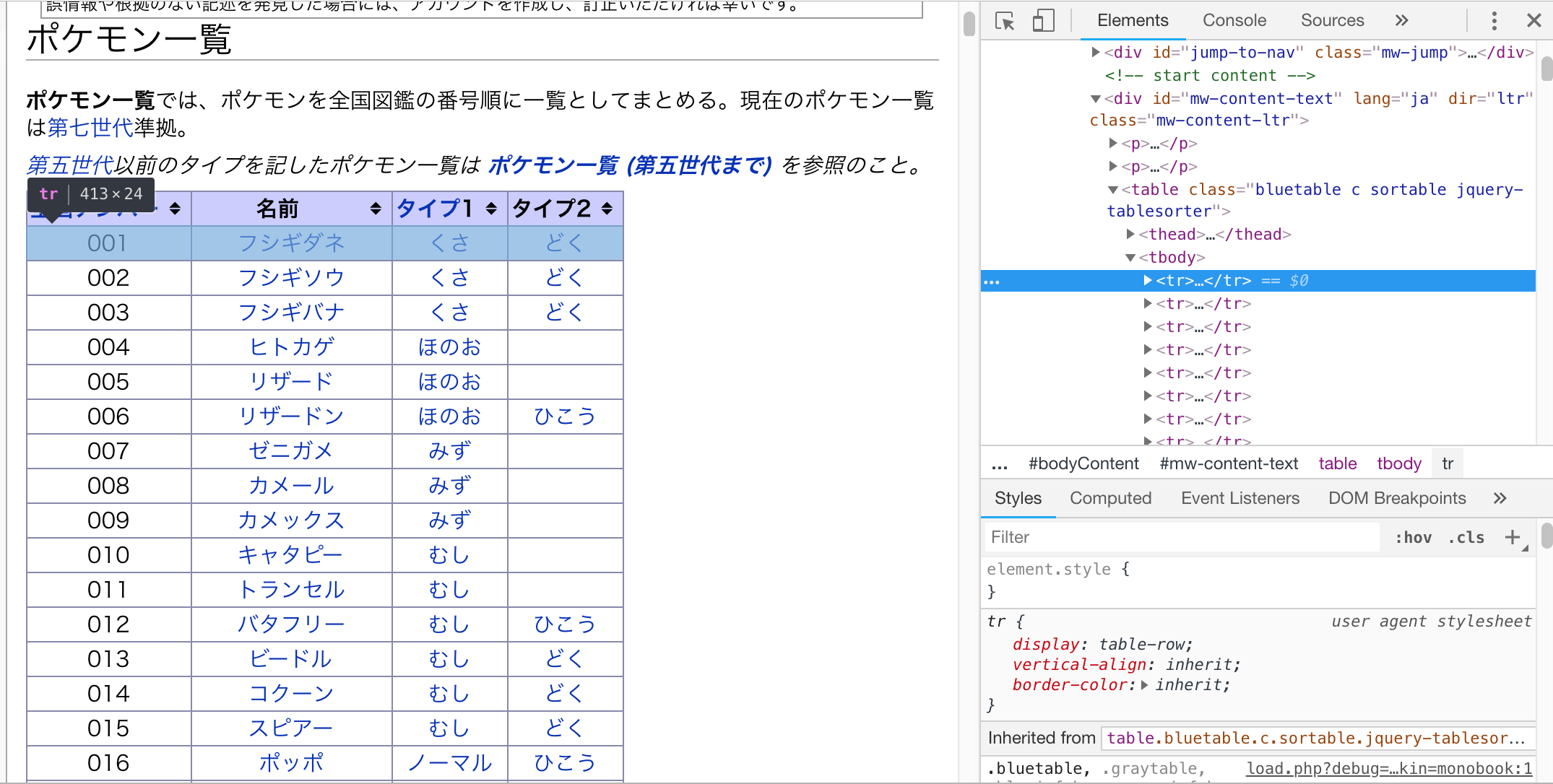
欲しい情報はがどのような構造になっているかを確認したら早速スクレイピングをしていきましょう。
単一要素の取得
まずは対象ページのポケモン一覧というタイトルを取得するプログラムで使い方を見ていきます。
ブラウザの検証機能で見てみると取得対象のタイトルにはfirstHeadingというidが指定されていることがわかります。
idは一般的には1ページにつき一つしか存在しないのでスクレイピングを行う際のセレクタとして使用するのにぴったりです。
それでは実際にコードを見ながら解説していきます。
require_once('./phpQuery-onefile.php');
$url = 'https://wiki.xn--rckteqa2e.com/wiki/%E3%83%9D%E3%82%B1%E3%83%A2%E3%83%B3%E4%B8%80%E8%A6%A7';
$html = file_get_contents($url);
$doc = phpQuery::newDocument($html);
$title = $doc->find('#firstHeading')->text();
// 確認
var_dump($title);
まず、1行目でphpQueryの読み込みを行っています。これを読み込むことによってphpでまるでjQueryのようにDOM操作を行うことが可能になります。
そして3-4行目で対象ページのURLからHTMLを取得して、6行目でDOM解析用のオブジェクトを生成しています。
8行目ではDOM解析用のオブジェクトからidがfirstHeadingのもののテキストを取得しています。
このプログラムをターミナルやコマンドプロンプトから実行してみます。
$ cd /your/path/to/scraping $ php index.php string(18) "ポケモン一覧"
見事にポケモン一覧というタイトルが取得できているのがわかります。
複数要素の取得
単一の要素の取得はできましたが今回欲しい情報はポケモンの情報になります。
ポケモンそれぞれの全国ナンバー、名前、タイプ1、タイプ2を取得したいのですが800匹を超える要素を一つ一つ上記のような書き方で取得していくのはあまりスマートではありません。
そこで、配列を使ってループ処理を行います。
require_once('./phpQuery-onefile.php');
$url = 'https://wiki.xn--rckteqa2e.com/wiki/%E3%83%9D%E3%82%B1%E3%83%A2%E3%83%B3%E4%B8%80%E8%A6%A7';
$html = file_get_contents($url);
$doc = phpQuery::newDocument($html);
foreach ($doc->find('#mw-content-text table.bluetable tr') as $tmp) {
$tr = pq($tmp);
if ($tr->find('td')->text()) {
$pokemon = [
'全国ナンバー' => $tr->find('td:nth-child(1)')->text(),
'名前' => $tr->find('td:nth-child(2)')->text(),
'タイプ1' => $tr->find('td:nth-child(3)')->text(),
'タイプ2' => $tr->find('td:nth-child(4)')->text(),
];
// 確認
var_dump($pokemon);
}
}
上記のコードで実際にポケモンの情報を取得することができます。
ここで注目するポイントは8行目と9行目です。
先程のタイトル取得のサイト同様、$doc->findで要素を指定していますが、先程は指定した要素が一つしか存在しなかったのに比べ、今回は指定している要素が複数存在しているため、phpQueryでは配列として使用することが可能です。
また、配列としてループをした場合、代入する変数に格納される要素は直接phpQueryで解析することができません。
そこで、pq()という関数を使用して$tmpを再度DOM解析用のオブジェクトとして生成し直しています。
その後は各trごとに$pokemonという変数に対応する値を格納しています。
このとき、nth-childというセレクタを使用していますがこれはCSSやjQueryで使うことができる疑似クラスです。
この他にもeqやeven、odd、gtなどjQueryで使用できる疑似セレクタが使用可能です。
先程のプログラム同様、ターミナルなどで実行してみてください。
$ php index.php
各ポケモンの情報がズラーッと表示されます。
再帰的な処理(クローリング)
これまでで一つのページからスクレイピングを行うことができるようになりました。
ですが、一つのページからのみデータを収集するのであれば取得対象によってはプログラムを作成するほうが時間がもったいない場合があります。
そこで、今回は先程までに取得したポケモンデータの他に、ポケモンの名前でリンクされている各ポケモンの詳細ページから、英語名も一緒に取得するプログラムを書いていきます。
require_once('./phpQuery-onefile.php');
$url = 'https://wiki.xn--rckteqa2e.com/wiki/%E3%83%9D%E3%82%B1%E3%83%A2%E3%83%B3%E4%B8%80%E8%A6%A7';
$html = file_get_contents($url);
$doc = phpQuery::newDocument($html);
foreach ($doc->find('#mw-content-text table.bluetable tr') as $tmp) {
$tr = pq($tmp);
if ($tr->find('td')->text()) {
$pokemon = [
'全国ナンバー' => $tr->find('td:nth-child(1)')->text(),
'名前' => $tr->find('td:nth-child(2)')->text(),
'タイプ1' => $tr->find('td:nth-child(3)')->text(),
'タイプ2' => $tr->find('td:nth-child(4)')->text(),
'詳細URL' => 'https://wiki.xn--rckteqa2e.com' . $tr->find('td:nth-child(2) a:nth-child(1)')->attr('href'),
];
$nxHtml = file_get_contents($pokemon['詳細URL']);
$nxDoc = phpQuery::newDocument($nxHtml);
foreach ($nxDoc->find('#mw-content-text table:nth-of-type(1) tr') as $tmp) {
$tt = pq($tmp);
if (strpos($tt->find('th')->text(),'英語名') !== false) {
$pokemon['英語名'] = $tt->find('td')->text();
}
}
// 確認
var_dump($pokemon);
// 5秒間のスリープ
sleep(5)
}
}
先程までに作成したスクレイピングプログラムにまずは17行目で詳細のURLを取得し、格納します。
HTMLタグに付与されているhrefやclassなどの属性値を取得するにはattr()を使用します。引数に取得したい属性名を渡してあげれば属性値が取得できます。
今回はaタグのhref属性の値を取得したいのでattr(‘href’)と指定しています。
また、ここで取得した値が相対パスの場合、それ単体ではURLとしては機能しないのでその前にhttpから始まるサイトドメインを追加します。
そして20-21行目で取得したURLを元に再度phpQueryを利用して詳細ページのDOM解析用オブジェクトを生成しています。
23-28行目では詳細ページの一番最初のテーブルから英語名と記載されている項目を探し、26行目で$pokemonに英語名というkeyで値を追加しています。
今回は複数ページを検証する時間がなかったのでこのような強引な使い方をしていますが、特定の要素を取り出してくる場合、foreachを使わずに下記のように記載してあげるのが標準です。
$pokemon['英語名'] = $nxDoc->find('#mw-content-text table:nth-of-type(1) tr:nth-child(2) td')->text();
この他にも先程のものに比べて追加されているもので重要なのが34行目のスリープになります。
詳しくは後述しますが複数ページをクローリングする場合は必ずスリープを入れましょう。
スクレイピングの注意点
この記事では再帰的な処理を行う簡単なクローラー&スクレイピングの方法をご紹介しましたがスクレイピングを行うにあたっていくつか注意しなければいけない点があります。
これらを知らずにスクレイピングを行っていくと知らないうちに最悪逮捕されてしまったなんてこともあり得るので十分に注意しながらスクレイピングを行ってください。
著作権と利用規約
取得したいサイトによっては利用規約でスクレイピング、クローリングが禁止されている場合があります。
このような場合、スクレイピングが検知されるとサイトにアクセスができなくなってしまうなんてことも。
恥ずかしながら僕もプログラムを始めたての頃に知らず、某有名サイトをスクレイピングしようとしてアク禁をくらった経験があります。
幸い僕は1週間程度で解除されましたが、知人の中にはずっとアクセス禁止になってしまった方もいますので十分に注意しましょう。
また、スクレイピングする情報の著作権についても注意が必要です。
著作権保護されているデータを取得して別サービスなどで公開したり、商用利用した場合などに法的に訴えられることもあるためスクレイピングを行う場合はしっかりと著作権表記などを確認してから行うようにしましょう。
robots.txtを遵守する
robots.txtとは、ボットなどのロボットに対してどのURLにアクセスしていいのか、どのようにアクセスしていいのかを記載しているファイルです。
robots.txtの以下の項目をしっかり確認の上、指示を遵守するようにしましょう。
| User-agent | 対象となるクローラーの種類(ユーザーエージェント) |
|---|---|
| Disallow | クロール、巡回を禁止するパス |
| Allow | クロール、巡回を許可するパス |
| Crawl-delay | クロールする際のアクセス間隔(秒) |
| Sitemap | サイトマップXMLのURL |
User-agentが*と指定されている場合はすべてのロボットが対象になります。
Disallowで指定されている巡回を禁止されているパスにはクローラーが行かないにしましょう。
また、サイトマップが存在する場合、サイトマップには各ページのURLが記載されているので、こちらを利用しましょう。
今回紹介したような通常のHTMLを読み込んで再帰的にクローリングを行う場合、HTMLを取得する必要があるので対象サイトにかかる負荷が大きくなります。
そういった負荷をすこしでも軽減するためにサイトマップは活用できます。
クロール間隔を空ける
robots.txtでも出てきましたが、Crawl-delayなどでクロールする際のアクセス間隔が指定されている場合はその間隔をしっかりと守りましょう。
Crawl-delayの指定がない場合も対象サイトによって最低でも1秒は間隔を空けるようにしましょう。
スクレイピングする際は対象のサイトに迷惑をかけないことが大前提です。
対象サイトのサーバーによっては短時間で大量のリクエストを行うことで高負荷に耐えられなくなり、サーバーがダウンしてしまうこともありえます。
その場合、岡崎市立中央図書館事件のように事件化してしまうなんてことにもなりかねないので気をつけましょう。
僕がクローラーを作成する際は基本的には5秒程度、小規模なサイトの場合は10〜25秒程度はアクセスに間隔をもたせています。
JSサイトのスクレイピング
最後におまけですがJavaScriptで生成されているコンテンツは、JSの実行後にコンテンツが生成されるため、PHPなどで単純にDOMを取得するだけではJSの実行ができず、思ったようにスクレイピングすることができません。
その場合はJSの実行が行えるヘッドレスブラウザと言われるものが必要になります。
PHPで進める場合はPhantomJSが有名ですが、既にサポートが終了していることもありあまりおすすめできません。
僕もまだ動作の確認はしていませんが、puphpeteerがいいかと思います。
ただ、本格的にクローリング、スクレイピングを行うのであればPHPではなくNodeやTypeScriptなどを使用するほうがいいかと思います。
僕のおすすめとしてはNodeとヘッドレスChromeのPuppeteerを使用しようしたクローリングです。